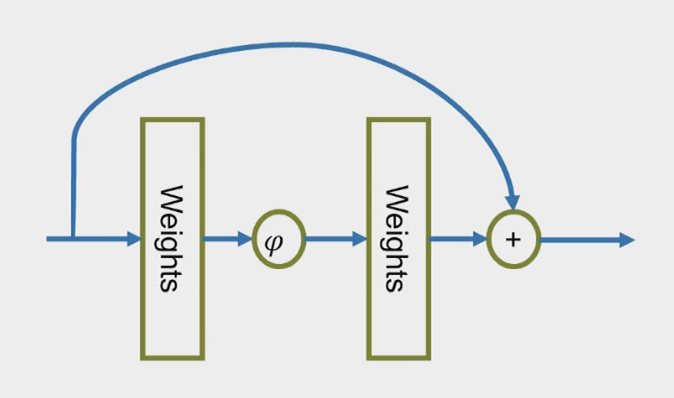
Residual connections
Introduce skip connections
- Helps avoid vanishing gradients
- Allows to train networks with 1000+ layers
- Skip more than one layer: DenseNets
Very common paradigm: train on large dataset for features, fine tune linear classifier on a different task with less available data